企业计算
[推荐]16nm工艺 英特尔放出Nervana NNP-T深度学习训练加速器
企业计算
7 年前
7.16W
现在深度学习已成为人工智能的重要方向,而且研究成果已经应用于日常使用中。但训练人工智能模型需要强大的算力支持,所以除了使用GPU加速训练外,很多厂商开始推出专用于深度学习训练的ASIC芯片。英特尔在人工智能领域投入颇多,除了FPGA产品线外,也推出了Nervana深度学习加速器,在今天的Hot Chips 31会议中,英特尔公布了旗下Nervana NNP-T深度学习加速器的细节。
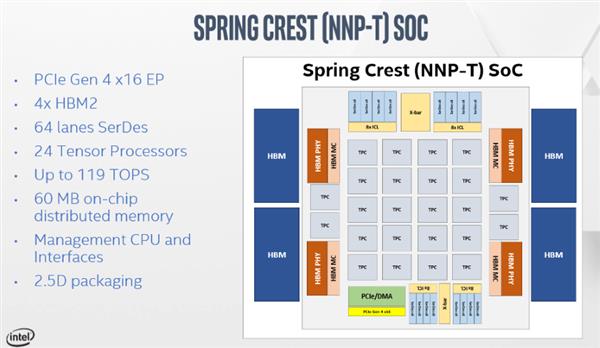
这款Nervana NNP-T深度学习加速器代号为Spring Cast,是目前英特尔最新款的专用深度学习加速器。这款加速器被命名为NNP-T,表示其主要用于深度学习网络模型训练工作定制。随着深度学习模型越来越庞大,所以专用的训练加速器也逐渐流行起来,如NVIDIA也推出了Tesla T4 GPU。
具体到加速器核心上,此次英特尔反常的使用了台积电16nm CLN16FF+工艺,而实际上Nervana在收购前就使用的是台积电28nm工艺制造其第一代的Lake Cast芯片。虽然使用的是台积电的工艺,但也是用了很多台积电的最新技术。芯片采用了4个8GB HBM2-2400内存,每针脚2.4GB/s的传输速率,都安装在一个巨大的1200平方毫米的硅基板上。同时计算核心与HBM内存通过台积电最新的CoWoS晶圆级封装技术进行互联。最终得到了一个60 x 60mm,具有3325 pin的BGA封装。
在展示中称此次由于HBM2与核心是无源封装,所以为2.5D封装技术。而HBM2由于是4Hi,所以整体为3D封装。实际上英特尔自家也有EMIB嵌入式多芯片互联桥接这种桥接技术。四个HBM2堆栈共有64条SerDes通道,每个通道支持28GB/s的传输速率。
具体的核心规模上,Nervana NNP-T的计算核心拥有270亿晶体管,包括24个Tensor Processors(TPC)。除了TPC外,芯片裸片中还有60MB的SRAM以及一些专用的接口,如IPMI、I2C及16条PCI-E 4.0通道。
芯片的工作频率为1.1GHz,风冷条件下功率配置为150W到250W,可通过水冷获得更强大的性能表现。同时Nervana NNP-T加速器还拥有OCP卡及PCI-E两种规格,以供数据中心选择。
Nervana NNP-T加速器充分利用内存模块和互联网络使得计算核心得以充分使用。计算核心支持bFloat16矩阵乘法、FP32、BF16以及其他主要操作。同时在使用上英特尔已经通过开源的nGraph库将深度学习框架连接到硬件后端的编译器。现在英特尔正在与常见的Paddle Paddle、Pytorch及TensorFlow深度学习框架进行合作。
由于采用了可扩展架构集OCP及PCI-E规格,所以对于数据中心等场景可以方便地进行扩展。架构支持扩展到1024个节点,每个节点拥有8个NNP-T计算核心。
本文由 Funstec非凡实验室 作者:Albert 发表,转载请注明来源!